


























































































'전체카테고리'에 해당되는 글 338건
- 2022.02.10 :: [신간소개] 보통의 취준생을 위한 코딩 테스트 with 파이썬: 백준 플래티넘 5 & 코드포스 파란색 랭크 달성하기
- 2022.02.10 :: [예제소스] 보통의 취준생을 위한 코딩 테스트 with 파이썬 : 백준 플래티넘 5 & 코드포스 파란색 랭크 달성하기
- 2022.02.10 :: [오탈자 정보] 보통의 취준생을 위한 코딩 테스트 with 파이썬 : 백준 플래티넘 5 & 코드포스 파란색 랭크 달성하기 2
- 2021.10.13 :: [신간소개] 백견불여일타 Node.js로 서버 만들기 2
- 2021.10.13 :: [예제소스] 백견불여일타 Node.js로 서버 만들기 1
- 2021.10.13 :: [오탈자 정보] 백견불여일타 Node.js로 서버 만들기 2
- 2021.08.26 :: [신간안내] 백견불여일타(이젠 프로젝트다!) 스프링 부트 쇼핑몰 프로젝트 with JPA 6
- 2021.08.26 :: [예제소스] 백견불여일타(이젠 프로젝트다!) 스프링 부트 쇼핑몰 프로젝트 with JPA
- 2021.08.26 :: [오탈자 정보] 백견불여일타(이젠 프로젝트다!) 스프링 부트 쇼핑몰 프로젝트 with JPA
- 2021.08.26 :: [신간안내] 사람과 프로그래머#11 나는 주니어 개발자다

● 저자: 권국원
● 페이지: 588
● 판형: 사륙배판변형(172*225)
● 도수: 2도
● 정가: 30,000원
● 발행일: 2022년 2월 22일
● ISBN: 978-89-97924-95-0 93000
네이버카페 바로가기 cafe.naver.com/codefirst
[강컴] [교보] [반디] [알라딘] [예스24] [인터파크]
_도서 내용
이 책은 손에 잡히는 코딩 테스트 합격 방법을 제시한다. 바로 “백준 플래티넘 5 & 코드 포스 파란색 랭크”로 목표 설정을 구체화한 것이다. 이 수준을 달성하면 웬만한 기업의 코딩 테스트 문제는 충분히 풀어낼 수 있다. 목표를 이루기 위해 단순히 기출문제를 많이 푸는 방식에서 벗어나, 학부 수준의 핵심 알고리즘 10개와 핵심 문제 60 개에 집중하여 자세한 해설과 함께 실었다. 이 책으로 기본기를 갖추고 다양한 문제를 혼자 힘으로 풀 수 있는 역량을 갖출 수 있을 것이다.
_대상 독자
_파이썬으로 기본적인 코딩을 할 수 있는 취준생
_알고리즘적 사고가 부족하다고 생각하여 코딩 근육을 키우고 싶은 개발자
_목차
저자서문
이 책으로 공부하는 방법
코딩 테스트 학습 로드맵 6단계
1부 코딩 테스트 워밍업
제1장 코딩 테스트 준비, 6개월이면 충분하다
1-1 코딩 테스트만 1년 간 죽어라 파보니
1-2 나의 스승인 <백준>과 <코드포스>
1-3 이것만 하면 대기업에 취업할 수 있다고?
1-4 너도 할 수 있어 6개월이면
문제_서로소
문제_A. Remove Smallest
제2장 코딩 테스트의 주적, 시간 복잡도
2-1 컴퓨터는 1초에 1억 번밖에 연산을 못하더라
시간복잡도가 O(n)인 경우
시간복잡도가 O(logn)인 경우
시간복잡도가 O(n^2)인 경우
시간복잡도가 O(2^n)인 경우
시간복잡도가 O(n!)인 경우
2-2 알고리즘 문제풀이에 시간복잡도 적용하기
문제_달팽이는 올라가고 싶다
제3장 카카오톡의 오픈채팅방은 무슨 알고리즘으로 구현할까?
3-1 카카오 개발자 신입 공개 채용 과정
3-2 2020년 카카오 개발자 신입 공개 채용 1차 1번 오픈채팅방 문제
3-3 카카오 코딩 테스트 그 이후
3-3-1 인프라 분야
3-3-2 프로그래밍 분야
문제_오픈채팅방(정답률 59.91%)
제4장 구현의 달인 삼성 코딩 테스트
4-1 삼성 개발자 신입 공개 채용 과정
4-2 삼성의 주력 서비스
4-3 삼성 S/W 역량 테스트 A형 기출 문제
4-4 삼성 코딩 테스트 그 이후
4-5 아! 알고리즘이란 컴퓨터에서 뗄 수 없는 존재구나
문제_치킨 배달
제5장 구현의 기초적인 문제
5-1 입출력에 관한 기본
5-1-1 출력
5-1-2 입력
5-2 if문
5-3 for문(컴퓨팅 사고력 향상)
5-3-1 for문 예제 1
5-3-2 for문 예제 2
5-3-3 for문 예제 3
5-4 함수
문제_Hello World
문제_사칙연산
문제_두 수 비교하기
문제_별 찍기–1
문제_별 찍기–2
문제_별 찍기–5
문제_사칙연산
2부 코딩 테스트 준비, 10가지 알고리즘이면 충분하다
제6장 ArrayList와 LinkedList–평생 사용해야 할 자료구조
6-1 ArrayList
6-1-1 ArrayList를 사용하는 예제
6-1-2 2차원 배열 사용 예제
6-1-3 삽입과 삭제가 많은 ArrayList의 잘못된 사용 예
6-2 LinkedList
6-2-1 LinkedList를 이용한 예제
문제_최소, 최대
문제_나는 요리사다
문제_크게 만들기
문제_요세푸스 문제
제7장 스택
7-1 스택
7-2 스택의 잘못된 사용 예와 잘 사용된 예
7-3 스택을 포함한 다양한 자료구조의 올바른 사용
7-4 스택을 사용하는 예제 1
7-5 스택을 사용하는 예제 2
7-6 스택을 사용하는 예제 3
문제_스택
문제_쇠막대기
문제_크게 만들기
제8장 큐
8-1 큐
8-2 큐를 사용하는 예제 1
8-3 큐를 사용하는 예제 2
8-4 큐를 사용하는 예제 3
문제_큐 2
문제_카드 2
문제_뱀
제9장 트리
9-1 트리
9-2 트리의 종류
9-2-1 이진트리
9-2-2 완전 이진트리
9-2-3 이진트리의 순회 및 예제
9-3 이진 검색 트리
9-4-1 이진 검색 트리 예제
문제_트리 순회
문제_이진 검색 트리
제10장 맵
10-1 맵
10-2 트리를 이용하여 구현하는 맵
10-3 해시를 이용하여 구현하는 맵
10-3–1 체이닝 방식
10-3–2 오픈 어드레싱 방식
10-4 맵을 사용하는 예제 1
10-5 맵을 사용하는 예제 2–<코드포스>
10-6 맵을 사용하는 예제 3–<코드포스>
문제_패션왕 신해빈
문제_D. Non-zero Segments
문제_D. MEX maximizing
제11장 힙, 우선순위 큐
11-1 힙
11-1-1 최대 힙
11-1-2 최소 힙
11-2 우선순위 큐
11-2-1 우선순위 큐를 사용하는 예제 1
11-2-2 우선순위 큐를 사용하는 예제 2
문제_최대 힙
문제_카드 정렬하기
제12장 탐욕법
12-1 탐욕법
12-2 탐욕법을 이용한 예제 1
12-3 탐욕법을 이용한 예제 2
12-4 탐욕법을 이용한 예제 3
12-5 탐욕법을 이용한 예제 4
12-6 탐욕법을 이용한 예제 5
문제_잃어버린 괄호
문제_회의실 배정
문제_소트1
문제_소트2
문제_대결
제13장 재귀와 분할정복
13-1 재귀
13-1-1 재귀를 이용한 예제 1
13-1-2 재귀를 이용한 예제 2
13-1-3 재귀를 이용한 예제 3
13-2 분할정복
13-2-1 분할정복을 이용한 예제 1
문제_팩토리얼
문제_하노이 탑 이동 순서
문제_파이프 옮기기 1
문제_색종이 만들기
제14장 완전 탐색
14-1 완전 탐색
14-2 순수 완전 탐색
14-2-1 순수 완전 탐색을 이용한 예제 1
14-2-2 순수 완전 탐색을 이용한 예제 2
14-2-3 순수 완전 탐색을 이용한 예제 3
14-3 백트래킹
14-3-1 백트래킹을 이용한 예제 1
14-3-2 백트래킹을 이용한 예제 2
14-3-3 백트래킹을 이용한 예제 3
문제_영화감독 숌
문제_체스판 다시 칠하기
문제_테트로미노
문제_N과 M (3)
문제_N과 M (1)
문제_연산자 끼워넣기
제15장 그래프
15-1 그래프 이론
15-2 BFS
15-2-1 BFS를 사용하는 예제 1
15-2-2 BFS를 사용하는 예제 2
15-2-3 BFS를 사용하는 예제 3
15-3 DFS
15-3-1 DFS를 사용하는 예제 1
15-3-2 DFS와 BFS를 사용하는 예제 1
문제_미로 탐색
문제_벽 부수고 이동하기
문제_연구소
문제_부분수열의 합
문제_DFS와 BFS
제16장 수학
16-1 수학
16-2 조합론
16-2–1 조합론 예제 1
16-2–2 조합론 예제 2–모듈러 연산
16-2–3 조합론 예제 3–코드포스
16-3 정수론
16-3-1 소수
16-3-2 소수를 이용한 예제 1
16-3-3 소수를 이용한 예제 2–코드포스
16-4 최대공약수와 최소공배수
16-4-1 최소공배수를 이용한 예제
문제_이항 계수 1
문제_이항 계수 2
문제_C. Kuroni and Impossible Calculation
문제_소수 구하기
문제_A. Tile Painting
문제_LCM
제17장 이분탐색
17-1 이분탐색
17-2 이분탐색을 이용한 예제 1
17-3 이분탐색을 이용한 예제 2
17-4 이분탐색을 이용한 예제 3
문제_수 찾기
문제_랜선 자르기
문제_개똥벌레
제18장 정렬
18-1 정렬
18-2 선택정렬
18-3 퀵정렬
18-4 정렬을 이용하는 예제 1, 2
18-5 정렬을 이용하는 예제 3
18-6 계수정렬
18-7 안정정렬과 불안정정렬
문제_수 정렬하기 1
문제_수 정렬하기 2
문제_저울
문제_수 정렬하기 3
문제_나이순 정렬
제19장 문자열
19-1 문자열
19-1-1 문자열을 이용한 예제 1
19-1-2 문자열을 이용한 예제 2
19-1-3 문자열을 이용한 예제 3
19-2 트라이 자료구조
19-2-1 트라이 자동구조를 이용한 예제
문제_숫자의 합
문제_백대열
문제_문자열 폭발
문제_전화번호 목록
제20장 동적 프로그래밍
20-1 동적 프로그래밍
20-2 동적 프로그래밍의 기본 예제 1
20-3 동적 프로그래밍의 기본 예제 2
20-4 동적 프로그래밍 완전 탐색
20-5 동적 프로그래밍–<코드포스>
20-6 2부를 마치며
문제_포도주 시식
문제_가장 긴 증가하는 부분수열
문제_내리막 길
문제_F1. Flying Sort (Easy Version)
부록 A 코딩 테스트 기출문제, 전공면접
A-1 삼성 S/W 역량 테스트를 풀어볼 수 있는 곳
A-2 카카오 신입공채 코딩 테스트 풀어보는 곳
A-3 전공 면접 준비
A-3-1 개발 상식
A-3-2 컴퓨터 네트워크
A-3-3 운영체제
A-3-4 컴퓨터구조
A-3-5 데이터베이스
A-3-6 그 밖의 질문들
부록 B 코드포스 대회
B-1 코드포스 대회 참가 경험
B-1-1 <코드포스> 대회 문제 A
B-1-2 <코드포스> 대회 문제 B
B-1-3 <코드포스> 대회 문제 C
B-2 <코드포스> 대회 참가 방법
찾아보기
_주요 내용
상세한 해설이 있는 엄선된 문제 60개로 실전에 대비한다
책의 특징
코딩 테스트만을 위한 빠른 학습 방법
백준과 코드 포스 출제 빈도별 학습 전략
단계별 학습 로드맵을 통한 체계적 공부법
카페에서 함께 공부하며 슬럼프 극복하기
대상 독자
이 책은 알고리즘 공부를 해도 실력이 늘지 않거나, 취업을 위해 코딩 테스트를 준비하고자 하는 독자, 단순히 알고리즘에 흥미가 생겨 공부를 시작해보려 하는 독자를 위한 책이다.
학습목표
이 책은 독자가 도달했으면 하는 분명한 목표가 있다. 백준 플래티넘 5, 코드 포스 파란색 랭크 달성이다. 이 정도의 랭크를 달성하면 거의 모든 기업의 코딩 테스트는 합격할 수 있다. 꼭 취준이 아니더라도 이 책을 가이드 삼아 6개월만 진정으로 시간을 투자해보자. 코딩이 정말 즐거워질 것이다. 코딩은 문제 해결 능력이 중요하며 코딩 테스트가 곧 이런 능력을 검증하는 시험이기 때문이다.
핵심 내용
_기본기를 다지기 위해 10개의 핵심 알고리즘에 집중한다
코딩 테스트는 대부분 대학 학부 수준의 10개의 핵심 알고리즘(자료구조 포함)에서 벗어나지 않는다. 1부에서 코딩 테스트를 어떻게 준비하면 되는지에 관한 워밍업을 하고 2부에서 10개의 핵심 알고리즘과 문제에 집중하면서 기초를 다질 수 있다.
_ 엄선된 60개의 문제를 통해 실전 감각을 익힌다
이 책은 다다익선이 아니라, 코딩 테스트 합격을 위한 최소한의 가이드라인에 집중하였다. 더 많은 문제를 풀어보고 도전할 수 있는 힘을 길러주는 것이 이 책의 목표이다. 혼자 시작하기 힘든 독자를 위해 스스로 공부할 수 있도록 엄선된 핵심 문제를 쉽고 자세하게 설명하였다.
“코딩 테스트를 준비하는 법부터 시작해서 기출 문제 풀이까지 코딩 테스트에서 중요한 내용을 꾺꾹 눌러담은 저자의 정성과 섬세함을 느낄 수 있었다. 처음 코딩 테스트를 준비하는 분들에게 좋은 길잡이가 될 것이다.”
_정재헌(실리콘밸리 스타트업 개발자, 소프트웨어 마에스트로12기)
_저자 소개
지은이
권국원
코딩을 배운다는 게 너무 막막하여 시작한 공부가 코딩 테스트였다. 개발자가 되기로 마음먹고 난 후 1년 간 코딩 테스트 공부에만 푹 빠져 지낸 덕분에 풀스택 개발자로 다양한 경험을 할 수 있었다.
지금은 소프트웨어 개발사를 만들어 하루하루 즐겁게 코딩을 하고 있다. 프로그래밍의 속도와 안전성을 최우선으로 생각하다 보니 개발을 하면서도 틈틈이 알고리즘 공부를 멈추지 않고 있다. 프로그램의 핵심기술 즉 코어라고 하는 부분을 만들기 위해서 알고리즘 학습의 중요성을 깨닫고 많은 사람에게 전파하기 위해 책을 집필하게 되었다.
나의 코딩 테스트 공부는 내가 개발하고 있는 동안은 계속될 것이다.
.
_상세 이미지

_끝
'신간소개' 카테고리의 다른 글
| [신간소개] 코딩의 미래: 인공지능이 최고의 코드를 만들어내는 세상이 온다_사람과 프로그래머 #12 (0) | 2022.06.08 |
|---|---|
| [신간소개] 암호화폐 자동매매 시스템 만들기 with 파이썬: 대량의 시뮬레이션과 최적화 전략까지 (4) | 2022.02.21 |
| [신간소개] 백견불여일타 Node.js로 서버 만들기 (2) | 2021.10.13 |
| [신간안내] 백견불여일타(이젠 프로젝트다!) 스프링 부트 쇼핑몰 프로젝트 with JPA (6) | 2021.08.26 |
| [신간안내] 사람과 프로그래머#11 나는 주니어 개발자다 (0) | 2021.08.26 |
예제소스는 아래 깃헙 사이트에서 다운로드 하실 수 있습니다.
https://github.com/rnjsrnrdnjs/Algorithm-code-for-coding-test
'자료실' 카테고리의 다른 글
| [도서자료] 개발자 상식: 개발자가 되기 전에 알았어야 할 것들 (0) | 2022.07.14 |
|---|---|
| [예제소스] 암호화폐 자동매매 시스템 만들기 with 파이썬: 대량의 시뮬레이션과 최적화 전략까지 (0) | 2022.02.21 |
| [예제소스] 백견불여일타 Node.js로 서버 만들기 (1) | 2021.10.13 |
| [예제소스] 백견불여일타(이젠 프로젝트다!) 스프링 부트 쇼핑몰 프로젝트 with JPA (0) | 2021.08.26 |
| [본문 예제소스] 백견불여일타 (이젠 프로젝트다!) 파이썬 생활밀착형 프로젝트: 웹크롤링, 카카오톡 메시지 보내기, 업무자동화까지11가지 파이썬 프로젝트 (0) | 2021.06.03 |
'오탈자 정보' 카테고리의 다른 글
| [오탈자 정보] 코딩의 미래: 인공지능이 최고의 코드를 만들어내는 세상이 온다_사람과 프로그래머 #12 (2) | 2022.06.08 |
|---|---|
| [오탈자 정보] 암호화폐 자동매매 시스템 만들기 with 파이썬: 대량의 시뮬레이션과 최적화 전략까지 (0) | 2022.02.21 |
| [오탈자 정보] 백견불여일타 Node.js로 서버 만들기 (2) | 2021.10.13 |
| [오탈자 정보] 백견불여일타(이젠 프로젝트다!) 스프링 부트 쇼핑몰 프로젝트 with JPA (0) | 2021.08.26 |
| [오탈자 정보] 사람과 프로그래머#11 나는 주니어 개발자다 (4) | 2021.08.26 |

● 저자: 박민경
● 페이지: 408
● 판형: 사륙배판형(188*257)
● 도수: 2도
● 정가: 27,000원
● 발행일: 2021년 10월 21일
● ISBN: 978-89-97924-90-5 93000
[강컴] [교보] [반디] [알라딘] [예스24] [인터파크]
[샘플원고]
_도서 내용
빠르게 실무형 Node.js 개발자가 될 수 있도록 도와주는 실습형 입문서다. 5줄로 만드는 Node.js 서버로 핵심 개념을 파악하고, 데이터베이스 연동, 실시간 통신 실습을 통해 실무형 개발 지식을 습득한 후, 페이스북 클론 코딩과 배포로 통합 실습을 해볼 수 있게 단계적으로 구성하였다. 페이스북 클론 프로젝트는 처음엔 따라해 보고, 그 다음엔 안 보고 만들어 보고, 그 다음엔 응용해서 좀더 확장된 여러 분의 버전을 만들어 보길 바란다.
_대상 독자
_Node.js를 기술 스택에 담고 싶어한다면
_당장 Node.js로 서버를 개발해야 한다면
_개발부터 배포까지 가능한 Node.js 토이 프로젝트를 찾고 있다면
_목차
목차
지은이의 글
일러두기
1장. Node.js 첫걸음
1.1 Node.js 첫걸음
웹 서버와 Node.js의 관계
Node.js가 동작하는 방식
1.2 실습을 위한 개발환경 구축
Node.js 설치
IDE(통합개발환경) 설치–비주얼 스튜디오 코드(Visual Studio Code, VS Code)
정리해봅시다
나의 이해도를 측정하자
2장. 자바스크립트 리마인드
2.1 자바스크립트 기본 문법
변수, 호이스팅, 클로저
객체와 배열
함수
프로토타입과 상속
2.2 자바스크립트의 비동기 처리
콜백 함수
Promise
async/await
비동기 상황에서의 예외 처리
정리해봅시다
나의 이해도를 측정하자
[함께해봐요 2-1] 변수 호이스팅 (sample01.js)
[함께해봐요 2-2] let을 사용한 변수 호이스팅 문제 해결 (sample02-1.js)
[함께해봐요 2-3] const를 사용한 변수 호이스팅 문제 해결 (sample02-2.js)
[함께해봐요 2-4] function-level-scope의 사용 ① (sample03.js)
[함께해봐요 2-5] function-level-scope의 사용 ② (sample04.js)
[함께해봐요 2-6] const의 특징 (sample05-1.js)
[함께해봐요 2-7] let의 특징 (sample05-1.js)
[함께해봐요 2-8] 클로저의 개념 (sample06.js)
[함께해봐요 2-9] 객체와 프로퍼티 (sample07.js)
[함께해봐요 2-10] 객체 배열 생성 (sample08.js)
[함께해봐요 2-11] 구조 분해 할당 (sample09.js)
[함께해봐요 2-12] 함수의 선언 (sample10.js)
[함께해봐요 2-13] 화살표 함수의 선언 (sample11.js)
[함께해봐요 2-14] this의 사용 (sample12.js)
[함께해봐요 2-15] bind 함수 사용 (sample12-2.js)
[함께해봐요 2-16] 프로토타입을 이용한 객체 생성 (sample13.js)
[함께해봐요 2-17] 프로토타입과 상속 (sample14.js)
[함께해봐요 2-18] Prototype Chaining (sample15.js)
[함께해봐요 2-19] 프로토타입을 클래스처럼 사용해보기 (sample16.js)
[함께해봐요 2-20] 콜백 함수의 비동기 처리 (sample17.js)
[함께해봐요 2-21] 콜백 함수의 동기 처리 (sample18.js)
[함께해봐요 2-22] 사용자 정의 함수의 동기 처리 (sample19.js)
[함께해봐요 2-23] API의 비동기적 처리 (sample20.js)
[함께해봐요 2-24] 일반 비동기 함수 (sample21-1.js)
[함께해봐요 2-25] 동기적 처리 ① (sample21-2.js)
[함께해봐요 2-26] 동기적 처리 ② (sample21-3.js)
[함께해봐요 2-27] Promise의 사용 (sample22.js)
[함께해봐요 2-28] Promise 객체와 async/await (sample23.js)
[함께해봐요 2-29] async/await의 사용 (sample24.js)
[함께해봐요 2-30] 사용자 정의 오류 (sample25.js)
[함께해봐요 2-31] 일반적인 예외 처리 (sample26.js)
[함께해봐요 2-32] .catch( )의 이용 (sample27.js)
[함께해봐요 2-33] .then( )의 이용 (sample27.js)
[함께해봐요 2-34] async/await의 예외 처리 ① (sample28-1.js)
[함께해봐요 2-35] async/await의 예외 처리 ② (sample28-2.js)
[함께해봐요 2-36] async/await의 예외 처리 ③ (sample28-3.js)
[함께해봐요 2-37] async/await의 예외 처리 ④ (sample28-4.js)
3장. 5줄로 만드는 서버
3.1 프로젝트의 시작
프로젝트 설정하기
NPM 명령어
3.2 Node.js의 모듈과 객체
모듈 시스템이란?
모듈의 종류
3.3 http 모듈로 서버 만들기
5줄로 서버를 만들어보자
요청 객체(req), 응답 객체(res)
3.4 express 모듈을 사용해 서버 만들기
express란?
express 설치와 사용
http 요청 메서드–GET, POST, PUT, PATCH, DELETE
3.5 express와 미들웨어
미들웨어란?
자주 사용하는 미들웨어
정리해봅시다
나의 이해도를 측정하자
[함께해봐요 3-1] A.js 소스 코드 (chapter03/sample/A.js)
[함께해봐요 3-2] B.js 소스 코드 (chapter03/sample/B.js)
[함께해봐요 3-3] 순환 참조 ① (chapter03/sample/A2.js)
[함께해봐요 3-4] 순환 참조 ② (chapter03/sample/B2.js)
[함께해봐요 3-5] 5줄로 만드는 서버 (chapter03/sample/simple_server.js)
[함께해봐요 3-6] 웹 페이지의 요청에 대한 응답 (chapter03/sample/simple_server2.js)
[함께해봐요 3-7] 문자열을 보내는 응답 코드 (chapter03/sample/simple_server3.js)
[함께해봐요 3-8] fs-test.html 작성 (chapter03/sample/fs_test.html)
[함께해봐요 3-9] 파일을 보내는 응답 코드 (chapter03/sample/fs_test.js)
[함께해봐요 3-10] request와 response 확인 (chapter03/sample/simple_sever3.js)
[함께해봐요 3-11] REST를 통한 페이지 생성 (chapter03/sample/simple_sever4.js)
[함께해봐요 3-12] express 사용법 ① (chapter03/express/express_study1.js)
[함께해봐요 3-13] express로 웹 페이지 만들기 (chapter03/express/index.html)
[함께해봐요 3-14] express 사용법 ② (chapter03/express/express_study2.js)
[함께해봐요 3-15] 미들웨어 사용법 ① (chapter03/express/express-study3.js)
[함께해봐요 3-16] 미들웨어 사용법 ② (chapter03/express/express_study4.js)
[함께해봐요 3-17] 오류 처리를 위한 미들웨어 함수 (chapter03/express/express_study5.js)
[함께해봐요 3-18] static 미들웨어 사용 ① (chapter03/express/express-study6.js)
[함께해봐요 3-19] static 미들웨어 사용 ② (chapter03/express/index2.html)
[함께해봐요 3-20] 미들웨어를 이용한 예제 ① (chapter03/express/express_study7.js)
[함께해봐요 3-21] 쿠키 전달 (chapter03/sample/cookie.js)
[함께해봐요 3-22] 세션을 통한 키 값 생성 (chapter03/sample/cookie-session.js)
[함께해봐요 3-23] 미들웨어 통합 테스트 (chapter03/express/express_study8.js)
4장. 통신을 구현해보자
4.1 API
API란?
Open API 활용 ①–request
Open API 활용 ②–axios
dotenv 사용하기
4.2 캐싱 구현하기
Redis란?
4.3 API 서버를 직접 만드는 방법
REST API
API 서버 만들기
API 서버 테스트 : CORS
4.4 웹 파싱
크롤링, 스크래핑, 파싱
정리해봅시다
나의 이해도를 측정하자
[함께해봐요 4-1] request 모듈로 네이버 API 사용해보기 (chapter04/sample/naver_request.js)
[함깨해봐요 4-2] axios 모듈로 에어코리아 API 사용해보기 (chapter04/sample/airkorea_axios.js)
[함께해봐요 4-3] 에어코리아 API 응답 결과 가져오기 (chapter04/sample/airkorea_axios2.js)
[함께해봐요 4-4] [함께해봐요 4-3]에 dotenv 모듈 적용 (chapter04/sample/airkorea_dotenv.js)
[함께해봐요 4-5] Redis 서버 테스트 ① (chapter04/sample/redis.js)
[함께해봐요 4-6] Redis 서버 테스트 ② (chapter04/sample/redis2.js)
[함께해봐요 4-7] [함께해봐요 4-3]에 캐시 적용하기 (chapter04/sample/redis3.js)
[함께해봐요 4-8] 내 API 서버 만들기 (chapter04/sample/colon_path.js)
[함께해봐요 4-9] 간단한 게시판 API 서버 만들기 (chapter04/sample/board_api.js)
[함께해봐요 4-10] uuid-apikey 모듈 사용 (chapter04/sample/uuid_apikey.js)
[함께해봐요 4-11] 게시판에 uuid-apikey 추가하기 (chapter04/sample/board_api2.js)
[함께해봐요 4-12] 게시판 API 서버 테스트 (chapter04/sample/board_api_test.js)
[함께해봐요 4-13] 게시판 API 서버 테스트 코드 작성 (chapter04/sample/board_api_test.html)
[함께해봐요 4-14] cors 모듈 설치 (chapter04/sample/board_api3.js)
[함께해봐요 4-15] 웹 페이지 크롤링 (chapter04/sample/crawling.js)
5장. Node.js와 데이터베이스
5.1 SQL과 NoSQL
SQL
NoSQL
5.2 SQL : MySQL
개발환경 설정
쿼리 기본 사용법
쿼리문 작성하기
ORM : Sequelize
5.3 NoSQL : MongoDB
MongoDB
정리해봅시다
나의 이해도를 측정하자
[함께해봐요 5-1] 데이터베이스 정보 저장 (chapter05/sequelize/config/config.json)
[함께해봐요 5-2] customer 객체를 ORM로 작성하기 (chapter05/sequelize/models/customer.js)
[함께해봐요 5-3] purchase 모델 생성 (chapter05/sequlieze/models/purchase.js)
[함께해봐요 5-4] index.js 수정 (chapter05/sequelize/models/index.js)
[함께해봐요 5-5] 테이블 관계 생성 (chapter05/sequelize/app.js )
[함께해봐요 5-6] 클라이언트 화면 생성 (chapter05/sequelize/customer.html)
[함께해봐요 5-7] 정보 입력창 서버 코드 (chapter05/sequelize/app2.js)
[함께해봐요 5-8] mongoose와 MongoDB 연결하기 (chapter05/mongoose/app.js)
6장. 실시간 통신을 구현해보자
6.1 웹 소켓
HTTP와 AJAX
웹 소켓
6.2 WS 모듈로 웹 소켓 구현하기
6.3 socket.io로 실시간 채팅 구현하기
6.4 실시간 채팅 구현하기
정리해봅시다
나의 이해도를 측정하자
[함께해봐요 6-1] ws 모듈을 이용한 WebSocket 구현 (chapter06/ws/socket.js)
[함께해봐요 6-2] 클라이언트 코드 작성 (chapter06/ws/index.html)
[함께해봐요 6-3] WebSocket 서버 코드 (chapter06/ws/app.js)
[함께해봐요 6-4] socket.io 모듈 불러오기 (chapter06/socket.io/app.js)
[함께해봐요 6-5] SocketIO 인스턴스 생성 (chapter06/socket.io/socket.js)
[함께해봐요 6-6] SocketIO 클라이언트 코드 (chapter06/socket.io/index.html)
[함께해봐요 6-7] SocketIO 클라이언트 코드에 polling 추가 (chapter06/socket.io/index.html)
[함께해봐요 6-8] 실시간 채팅창 구현하기 (chapter06/chat/app.js)
[함께해봐요 6-9] CSS 파일 생성 (chapter06/chat/index.css)
[함께해봐요 6-10] 실시간 채팅창 클라이언트 코드 ① (chapter06/chat/index.html)
[함께해봐요 6-11] 실시간 채팅창 클라이언트 코드 ② (chapter06/chat/index.html)
7장. 토이 프로젝트 : 페이스북 클론 코딩
7.1 passport
passport란?
passport 사용하기
7.2 템플릿 엔진
정적 파일과 동적 파일
템플릿 엔진
7.3 토이 프로젝트 : 페이스북 클론 코딩
정리해봅시다
나의 이해도를 측정하자
[함께해봐요 7-1] 회원가입 화면 코드 (chapter07/ex_passport/index.html)
[함께해봐요 7-2] passport를 이용한 회원가입 서버 코드 (chapter07/ex_passport/app.js 1~32행)
[함께해봐요 7-3] passport를 이용한 회원가입 서버 코드 수정 ① (chapter07/ex_passport/app.js 34~62행)
[함께해봐요 7-4] passport를 이용한 회원가입 서버 코드 수정 ② (chapter07/ex_passport/app.js 64~119행)
[함께해봐요 7-5] index.js 파일 생성 (chapter07/ejs/index.js)
[함께해봐요 7-6] index.ejs 파일 생성 (chapter07/ejs/views/index.ejs)
[함께해봐요 7-7] head.js 파일 작성 (Chapter07/ejs/views/partials/head.ejs)
[함께해봐요 7-8] header.ejs 파일 작성 (Chapter07/ejs/views/partials/header.ejs)
[함께해봐요 7-9] footer.ejs 파일 작성 (Chapter07/ejs/views/partials/footer.ejs)
[함께해봐요 7-10] 조각난 파일을 하나로 모으기 (Chapter07/ejs/views/index2.ejs)
[함께해봐요 7-11] 메뉴의 라우터를 index2.js에서 생성 (Chapter07/ejs/index2.js)
[함께해봐요 7-12] package.json 파일 수정 (facebook-clone/package.json 6~8행)
[함께해봐요 7-13] app.js 파일 수정 ① (facebook-clone/app.js 1~11행)
[함께해봐요 7-14] app.js 파일 수정 ② (facebook-clone/app.js 13~22행)
[함께해봐요 7-15] app.js 파일 수정 ③ (facebook-clone/app.js 24~32행)
[함께해봐요 7-16] .env 파일 생성 (facebook-clone/.env)
[함께해봐요 7-17] app.js 파일 수정 ④ (facebook-clone/app.js 34~44행)
[함께해봐요 7-18] app.js 파일 수정 ⑤ (facebook-clone/app.js 46~58행)
[함께해봐요 7-19] app.js 파일 수정 ⑥ (facebook-clone/app.js 60~67행)
[함께해봐요 7-20] app.js 파일 수정 ⑦ (facebook-clone/app.js 69~75행)
[함께해봐요 7-21] app.js 파일 수정 ⑧ (facebook-clone/app.js 77~110행)
[함께해봐요 7-22] User.js 파일 작성 (facebook-clone/models/User.js)
[함께해봐요 7-23] Post.js 파일 작성 (facebook-clone/models/Post.js)
[함께해봐요 7-24] Comment.js 파일 작성 (facebook-clone/models/Comment.js)
[함께해봐요 7-25] User.js 파일 수정 ① (facebook-clone/routes/user.js 1~22행)
[함께해봐요 7-26] User.js 파일 수정 ② (facebook-clone/routes/users.js 24~29행)
[함께해봐요 7-27] .env 파일 작성 (facebook-clone/.env)
[함께해봐요 7-28] User.js 파일 수정 ③ (fackebook-clone/routes/users.js 31~38행)
[함께해봐요 7-29] User.js 파일 수정 ④ (facebook-clone/routes/users.js 40~83행)
[함께해봐요 7-30] User.js 파일 수정 ⑤ (facebook-clone/routes/users.js 85~119행)
[함께해봐요 7-31] User.js 파일 수정 ⑥ (facebook-clone/routes/users.js 121~278행)
[함께해봐요 7-32] User.js 파일 수정 ⑦ (facebook-clone/routes/users.js 280~298행)
[함께해봐요 7-33] post.js 파일 작성 (facebook-clone/routes/posts.js)
8장. 서버를 배포해보자
8.1 기본 준비
cross-env 설정하기
morgan, winston 설정하기
express-session 수정하기
보안 관련 모듈 추가하기
깃, 깃허브 사용하기
더 나아가기 : pm2와 메모리 DB
8.2 클라우드 서비스
8.3 클라우드 호스팅 서비스 : Heroku
8.4 도커 사용하기
도커란?
도커 기본 사용법
8.5 클라우드 인프라 서비스 : AWS EC2
AWS 계정 생성
EC2 인스턴스 생성
도커와 깃허브를 이용해서 EC2에 배포하기
정리해봅시다
나의 이해도를 측정하자
[함께해봐요 8-1] package.json 파일 수정 ① (facebook-clone/package.json)
[함께해봐요 8-2] winston.js 파일 수정 (facebook-clone/config/winston.js)
[함께해봐요 8-3] app.js 파일 수정 ① (facebook-clone/app.js)
[함께해봐요 8-4] app.js 파일 수정 ② (facebook-clone/app.js)
[함께해봐요 8-5] app.js 파일 수정 ③ (facebook-clone/app.js)
[함께해봐요 8-6] post.js 파일 수정 (facebook-clone/routs/posts.js)
[함께해봐요 8-7] users.js 파일 수정 (facebook-clone/routes/users.js)
[함께해봐요 8-8] login.ejs 파일 수정 (facebook-clone/views/users/login.ejs)
[함께해봐요 8-9] .env 파일 수정 (facebook-clone/.env)
[함께해봐요 8-10] app.js 파일 수정 ④ (facebook-clone/app.js)
[함께해봐요 8-11] package.json 파일 수정 ② (facebook-clone/package.json)
참고 링크
전체 소스코드 및 연습문제 풀이 해답 저장소
찾아보기
_주요 내용
빠르게 실무형 Node.js 개발자가 될 수 있도록 도와주는 실습형 입문서
_5줄 서버
_캐싱
_API 서버
_데이터베이스 연동
_실시간 통신
_페이스북 클론 코딩까지
“기초를 다질 수 있도록”
이 책에서 다루는 Node.js라는 기술은 자바스크립트를 알아야 사용할 수 있는 환경입니다. 하지만 자바스크립트에 익숙하지 않아도 프로그래밍이 어떤 것인지 기본 개념만 있으면 따라할 수 있도록 구성하였습니다.
“개발은 만들어보는 것”
서버 로직을 만든다는 것은 화면 개발처럼 시각적으로 눈에 보이는 결과가 나오는 것이 아니므로 어쩌면 ‘서버’라는 개념이 뜬구름 잡는 소리처럼 느껴질 수 있습니다. 그러므로 예제를 통해 개념과 원리를 서서히 습득하고 이해할 수 있도록 하였습니다.
“연습문제를 직접 풀어보지 않으면 아무리 좋은 입문서라도 백약이 무효입니다.”
직접 해보고 반복해서 학습해보는 것만이 낯설음을 익숙함으로 바꿀 수 있는 유일한 길입니다. 힌트까지 제공되니 반드시 혼자만의 힘으로 풀어보고 저자의 모범답안과 비교해보세요.
“토이 프로젝트로 빠르게 실무형 개발에 적응하자”
6장까지는 웹 서비스에 필요한 내용을 조각조각 나누어 살펴보았다면, 7장과 8장에서는 토이 프로젝트를 통해 내가 가진 조각들로 하나의 덩어리를 만들어 볼 수 있습니다. ‘클론 코딩’을 통해 서비스에 대한 전체적인 흐름을 익히고 배포까지 완벽하게 하나의 프로젝트 사이클을 경험해 봅니다. 많이 따라해보고 익숙해져서 내 것으로 만들어 보세요.
_저자 소개
지은이
박민경
건국대 소프트웨어공학과를 졸업하였으며, 과거 파이썬 케라스 및 Node.js 스택을 다루며 챗봇 프로젝트에 참여했고 현재 여행 산업에서 Tech를 적용하기 위한 테크투어 스타트업에서 개발자로 근무 중이다. 전공과정 및 크고 작은 프로젝트를 통해 습득한 Computer Science 지식을 이해하기 쉽게 전달하기 위해 개발 블로그를 운영 중이며, 개발자만을 위한 개발 문화가 아닌 다양한 사람들과 함께하는 개발 문화를 만들어가는 데 관심이 많다
.
_상세 이미지

_끝
'신간소개' 카테고리의 다른 글
| [신간소개] 암호화폐 자동매매 시스템 만들기 with 파이썬: 대량의 시뮬레이션과 최적화 전략까지 (4) | 2022.02.21 |
|---|---|
| [신간소개] 보통의 취준생을 위한 코딩 테스트 with 파이썬: 백준 플래티넘 5 & 코드포스 파란색 랭크 달성하기 (0) | 2022.02.10 |
| [신간안내] 백견불여일타(이젠 프로젝트다!) 스프링 부트 쇼핑몰 프로젝트 with JPA (6) | 2021.08.26 |
| [신간안내] 사람과 프로그래머#11 나는 주니어 개발자다 (0) | 2021.08.26 |
| [신간안내] 백견불여일타 (이젠 프로젝트다!) 파이썬 생활밀착형 프로젝트: 웹크롤링, 카카오톡 메시지 보내기, 업무자동화까지11가지 파이썬 프로젝트 (0) | 2021.06.03 |
전체 소스코드 및 연습문제 풀이 해답 저장소
'자료실' 카테고리의 다른 글
| [예제소스] 암호화폐 자동매매 시스템 만들기 with 파이썬: 대량의 시뮬레이션과 최적화 전략까지 (0) | 2022.02.21 |
|---|---|
| [예제소스] 보통의 취준생을 위한 코딩 테스트 with 파이썬 : 백준 플래티넘 5 & 코드포스 파란색 랭크 달성하기 (0) | 2022.02.10 |
| [예제소스] 백견불여일타(이젠 프로젝트다!) 스프링 부트 쇼핑몰 프로젝트 with JPA (0) | 2021.08.26 |
| [본문 예제소스] 백견불여일타 (이젠 프로젝트다!) 파이썬 생활밀착형 프로젝트: 웹크롤링, 카카오톡 메시지 보내기, 업무자동화까지11가지 파이썬 프로젝트 (0) | 2021.06.03 |
| [본문 예제소스] 백견불여일타 머신러닝 데이터 전처리 입문 (2) | 2020.09.07 |
'오탈자 정보' 카테고리의 다른 글
| [오탈자 정보] 암호화폐 자동매매 시스템 만들기 with 파이썬: 대량의 시뮬레이션과 최적화 전략까지 (0) | 2022.02.21 |
|---|---|
| [오탈자 정보] 보통의 취준생을 위한 코딩 테스트 with 파이썬 : 백준 플래티넘 5 & 코드포스 파란색 랭크 달성하기 (2) | 2022.02.10 |
| [오탈자 정보] 백견불여일타(이젠 프로젝트다!) 스프링 부트 쇼핑몰 프로젝트 with JPA (0) | 2021.08.26 |
| [오탈자 정보] 사람과 프로그래머#11 나는 주니어 개발자다 (4) | 2021.08.26 |
| [오탈자 정보] 백견불여일타 (이젠 프로젝트다!) 파이썬 생활밀착형 프로젝트: 웹크롤링, 카카오톡 메시지 보내기, 업무자동화까지11가지 파이썬 프로젝트 (0) | 2021.06.03 |

● 저자: 변구훈
● 페이지: 372
● 판형: 사륙배판형(188*257)
● 도수: 2도
● 정가: 30,000원
● 발행일: 2021년 9월 7일
● ISBN: 978-89-97924-89-9 93000
[강컴] [교보] [반디] [알라딘] [예스24] [인터파크]
[샘플원고]
_도서 내용
스프링 부트와 JPA를 활용하여 실제 이커머스 업계에서 활용되는 쇼핑몰 기술들을 직접 구현해볼 수 있게 구성하였다. JPA와 Thymeleaf에 대한 간단한 예제로 기본 개념과 사용법을 익히고 그 후 쇼핑몰의 기본적인 기능들을 구현해 가며 JPA와 스프링 부트를 자연스레 익힐 수 있다. "Just Do It" 컨셉을 통해 하나의 완성된 서비스를 만드는 것을 목표로 하며 복잡한 코드 없이 최대한 간결한 코드 위주로 작성하였다. 이 책을 참고하여 자신만의 포트폴리오를 만들어보는 것도 가능하다. 테스트 코드를 작성하면서 개발을 진행하는 TDD 방식을 적용하였기 때문에 실무지향적 특성까지 갖추었다.
_대상 독자
_다음과 같은 선수 지식이 있는 독자
Spring Framework를 어느 정도 사용해 보았다.
데이터베이스에 대한 기초적인 지식을 가지고 있다.
Java 언어에 대한 기초적인 지식이 있다.
HTM, JavaScript. CSS에 대한 기초적인 지식이 있다.
_다음과 같은 목표를 갖고 있는 독자
Spring Boot와 Spring Data JPA를 사용해서 작은 서비스를 처음부터 끝까지 구축해보고 싶다.
_목차
지은이의 말
베타테스터의 말
일러두기
1장 개발 환경 구축
1.1 스프링 부트의 특징
1.2 JDK 설치
1.3 인텔리제이 설치
1.4 애플리케이션 실행하기
1.4.1 Spring Boot Project 생성하기
1.4.2 빌드 도구
1.4.3 설정 파일(application.properties)
1.4.4 Hello World 출력하기
1.5 Lombok 라이브러리
1.6 MySQL 설치하기
[함께 해봐요 1-1] application.properties 설정하기
[함께 해봐요 1-2] Hello World 출력하기
[함께 해봐요 1-3] 애플리케이션 포트 변경하기
[함께 해봐요 1-4] Lombok 라이브러리 적용하기
2장 Spring Data JPA
2.1 JPA
2.1.1 JPA란?
2.1.2 JPA 동작 방식
2.2 쇼핑몰 프로젝트 생성하기
2.2.1 프로젝트 생성하기
2.2.2 application.properties 설정하기
2.3 상품 엔티티 설계하기
2.3.1 상품 엔티티 설계하기
2.4 Repository 설계하기
2.5 쿼리 메소드
2.6 Spring DATA JPA @Query 어노테이션
2.7 Spring DATA JPA Querydsl
[함께 해봐요 2-1] 상품 클래스 생성하기_Ver01
[함께 해봐요 2-2] 상품 클래스 엔티티 매핑_Ver02
[함께 해봐요 2-3] 상품 Repository 작성 및 테스트하기
[함께 해봐요 2-4] 쿼리 메소드를 이용한 상품 조회하기
[함께 해봐요 2-5] OR 조건 처리하기
[함께 해봐요 2-6] LessThan 조건 처리하기
[함께 해봐요 2-7] OrderBy로 정렬 처리하기
[함께 해봐요 2-8] @Query를 이용한 검색 처리하기
[함께 해봐요 2-9] @Query–nativeQuery 속성 예제
[함께 해봐요 2-10] JPAQueryFactory를 이용한 상품 조회 예제
[함께 해봐요 2-11] QuerydslPredicateExecutor를 이용한 상품 조회 예제
3장 Thymeleaf 학습하기
3.1 Thymeleaf 소개
3.2 Spring Boot Devtools
3.2.1 Automatic Restart 적용하기
3.2.2 Live Reload 적용하기
3.2.3 Property Defaults 적용하기
3.3 Thymeleaf 예제 진행하기
3.3.1 th:text 예제
3.3.2 th:each 예제
3.3.3 th:if, th:unless 예제
3.3.4 th:switch, th:case 예제
3.3.5 th:href 예제
3.4 Thymeleaf 페이지 레이아웃
3.4.1 Thymeleaf Layout Dialect dependency 추가하기
3.5 부트스트랩으로 header, footer 영역 수정하기
3.5.1 Bootstrap CDN 추가하기
3.5.2 Bootstrap Navbar Component 활용하기
[함께 해봐요 3-1] 웹 브라우저에서 Thymeleaf 파일 열어보기
[함께 해봐요 3-2] Thymeleaf 예제용 컨트롤러 클래스 만들기
[함께 해봐요 3-3] 서버용 Thymeleaf 파일
[함께 해봐요 3-4] pom.xml에 의존성 추가하기
[함께 해봐요 3-5] application.properties Live Reload 적용 설정 추가하기
[함께 해봐요 3-6] application.properties Property Defaults 설정 추가하기
[함께 해봐요 3-7] th:text를 이용한 상품 데이터 출력용 Dto 클래스
[함께 해봐요 3-8] th:text를 이용한 상품 데이터 출력용 컨트롤러 클래스
[함께 해봐요 3-9] th:text를 이용한 상품 데이터 출력용 thymeleaf 파일
[함께 해봐요 3-10] th:each를 이용한 상품 리스트 출력용 컨트롤러
[함께 해봐요 3-11] th:each를 이용한 상품 리스트 출력용 thymeleaf 파일
[함께 해봐요 3-12] th:if, th:unless를 이용한 조건문 처리용 컨트롤러 작성하기
[함께 해봐요 3-13] th:if, th:unless를 이용한 조건문 처리용 thymeleaf 파일 만들기
[함께 해봐요 3-14] th:switch, th:case를 이용한 조건문 처리용 thymeleaf 파일
[함께 해봐요 3-15] th:href를 이용한 링크 처리용 컨트롤러
[함께 해봐요 3-16] th:href를 이용한 링크 처리용 thymeleaf 파일
[함께 해봐요 3-17] th:href를 이용한 파라미터 데이터 전달용 thymeleaf 파일
[함께 해봐요 3-18] th:href를 이용한 파라미터 데이터 전달용 컨트롤러 작성하기
[함께 해봐요 3-19] th:href를 이용한 파라미터 데이터 전달용 thymeleaf 파일
[함께 해봐요 3-20] pom.xml에 Thymeleaf Layout Dialect 의존성 추가하기
[함께 해봐요 3-21] Thymeleaf 페이지 레이아웃 예제: 푸터 만들기
[함께 해봐요 3-22] Thymeleaf 페이지 레이아웃 예제: 헤더 만들기
[함께 해봐요 3-23] Thymeleaf 페이지 레이아웃 예제: 본문 레이아웃
[함께 해봐요 3-24] Thymeleaf 페이지 레이아웃 예제: thymeleaf 파일 만들기
[함께 해봐요 3-25] Thymeleaf 페이지 레이아웃 예제: 컨트롤러 클래스 작성하기
[함께 해봐요 3-26] 레이아웃에 Bootstrap CDN 추가하기
[함께 해봐요 3-27] 헤더 영역에 Navbar 추가하기
[함께 해봐요 3-28] 푸터 영역 수정하기
[함께 해봐요 3-29] CSS 적용하기
[함께 해봐요 3-30] CSS와 HTML 파일 연결하기
4장 스프링 시큐리티를 이용한 회원 가입 및 로그인
4.1 스프링 시큐리티 소개
4.2 스프링 시큐리티 설정 추가하기
4.2.1 security dependency 추가하기
4.2.2 스프링 시큐리티 설정하기
4.3 회원 가입 기능 구현하기
4.4 로그인/로그아웃 구현하기
4.4.1 UserDetailsService
4.4.2 UserDetail
4.4.3 로그인/로그아웃 구현하기
4.5 페이지 권한 설정하기
[함께 해봐요 4-1] 스프링 시큐리티 로그인하기
[함께 해봐요 4-2] SecurityConfig 클래스 작성하기
[함께 해봐요 4-3] 회원 가입 기능 구현하기
[함께 해봐요 4-4] 회원 가입 기능 테스트하기
[함께 해봐요 4-5] 회원 가입 페이지 작성하기
[함께 해봐요 4-6] 회원 가입 컨트롤러 소스코드 작성하기
[함께 해봐요 4-7] 회원 가입 처리하기
[함께 해봐요 4-8] 로그인/로그아웃 기능 구현하기
[함께 해봐요 4-9] 로그인 테스트하기
[함께 해봐요 4-10] 로그인/로그아웃 화면 연동하기
[함께 해봐요 4-11] 페이지 권한 설정하기
[함께 해봐요 4-12] 유저 접근 권한 테스트하기
5장 연관 관계 매핑
5.1 연관 관계 매핑 종류
5.1.1 일대일 단방향 매핑하기
5.1.2 다대일 단방향 매핑하기
5.1.3 다대일/일대다 양방향 매핑하기
5.1.4 다대다 매핑하기
5.2 영속성 전이
5.2.1 영속성 전이란?
5.2.2 고아 객체 제거하기
5.3 지연 로딩
5.4 Auditing을 이용한 엔티티 공통 속성 공통화
[함께 해봐요 5-1] 장바구니 엔티티 설계하기
[함께 해봐요 5-2] 장바구니 엔티티 조회 테스트하기(즉시 로딩)
[함께 해봐요 5-3] 장바구니 아이템 엔티티 설계하기
[함께 해봐요 5-4] 주문 도메인 엔티티 설계하기
[함께 해봐요 5-5] 주문 영속성 전이 테스트하기
[함께 해봐요 5-6] 고아 객체 제거 테스트하기
[함께 해봐요 5-7] 주문 엔티티 조회 테스트하기(즉시 로딩)
[함께 해봐요 5-8] 엔티티 지연 로딩 설정하기
[함께 해봐요 5-9] Auditing 기능을 활용한 데이터 추적하기
6장 상품 등록 및 조회하기
6.1 상품 등록하기
6.2 상품 수정하기
6.3 상품 관리하기
6.4 메인 화면
6.5 상품 상세 페이지
[함께 해봐요 6-1] 상품 등록 구현하기
[함께 해봐요 6-2] 상품 수정하기
[함께 해봐요 6-3] 상품 관리 메뉴 구현하기
[함께 해봐요 6-4] 메인 페이지 구현하기
7장 주문
7.1 주문 기능 구현하기
7.2 주문 이력 조회하기
7.3 주문 취소하기
[함께 해봐요 7-1] 주문 기능 구현하기
[함께 해봐요 7-2] 주문 기능 테스트하기
[함께 해봐요 7-3] 주문 호출 구현하기
[함께 해봐요 7-4] 구매 이력
[함께 해봐요 7-5] 주문 취소 기능 구현하기
[함께 해봐요 7-6] 주문 취소 테스트하기
[함께 해봐요 7-7] 주문 취소 호출 구현하기
8장 장바구니
8.1 장바구니 담기
8.2 장바구니 조회하기
8.3 장바구니 상품 주문하기
[함께 해봐요 8-1] 장바구니 담기 구현하기
[함께 해봐요 8-2] 장바구니 담기 테스트하기
[함께 해봐요 8-3] 장바구니 담기 호출 구현하기
[함께 해봐요 8-4] 장바구니 조회하기
[함께 해봐요 8-5] 장바구니 상품 수량 변경하기
[함께 해봐요 8-6] 장바구니 상품 삭제하기
[함께 해봐요 8-7] 장바구니 상품 주문하기
_주요 내용
기본 예제를 통해서 Thymeleaf, Spring Data JPA의 사용법을 익히고 스프링 부트 위에서 상품, 주문, 장바구니 도메인 로직을 구현해보도록 구성하였다. 끝까지 따라하며 배워나가면 앞으로 다른 프로젝트를 시작할 때 기반이 되는 기술을 습득할 수 있으며, 이커머스에 관심이 많은 초보 개발자 여러분의 포트폴리오 제작에도 도움이 될 것이다.
[선수지식]
- Java 언어에 대한 기본 지식
- SQL에 대한 기본 지식
- MVC 기반의 웹 프로그래밍 경험
[이 책의 주요 특징]
- Spring Boot 프로젝트 기본 설정
- Spring Data JPA에 대한 기본 예제 수록
- Junit을 이용한 테스트 코드 작성
- Thymeleaf를 이용한 화면 구성
- Spring Security를 이용하여 회원 인증 및 인가 기능 구현
_베타테스터 김지영(에스에스지닷컴)
이 책을 읽다 보면 프로젝트 패키지 구성부터 메이븐을 통한 빌드 구성과 같이 기초부터 시작해 실무에서는 몰랐던 내용들을 배울 수 있다. 실습을 모두 따라 하면 흔히 볼 수 있는 쇼핑몰의 기능을 모두 구현할 수 있어 재미도 느낄 수 있을 것이다.
_베타테스터 정선민(에스에스지닷컴)
현업에서 처음 개발을 해보는 주니어 개발자는 개념은 알지만 실제로 어떻게 구현해야 할지 고민을 많이 하게 된다. 이 책은 기본적인 개념을 설명한 뒤 구현된 코드를 보여주고 그 코드에 개념이 어떻게 녹아 있는지 설명하는 방식이기 때문에 처음 프로젝트를 시작하는 개발자도 쉽게 학습할 수 있다.
베타테스터 권샘찬(키위스튜디오)
_저자 소개
지은이
변구훈
컴퓨터 공학을 전공하였으며, 현재 이커머스 회사에서 제휴사 상품 연동 및 어드민 개발을 맡고 있다. 하루에 몇천만 건의 데이터를 연동하면서 백엔드 엔지니어로 성장 중이다. 새로운 지식을 배우고, 배운 내용을 토대로 실제 서비스를 개발하여 사용자들에게 배포하는 데 관심이 많다.
현재까지 개발해서 사람들에게 배포해본 서비스가 3가지 정도 된다. 개인 블로그 운영이 인연이 되어 집필까지 진행하게 되었다.
_상세 이미지

_끝
'신간소개' 카테고리의 다른 글
| [신간소개] 보통의 취준생을 위한 코딩 테스트 with 파이썬: 백준 플래티넘 5 & 코드포스 파란색 랭크 달성하기 (0) | 2022.02.10 |
|---|---|
| [신간소개] 백견불여일타 Node.js로 서버 만들기 (2) | 2021.10.13 |
| [신간안내] 사람과 프로그래머#11 나는 주니어 개발자다 (0) | 2021.08.26 |
| [신간안내] 백견불여일타 (이젠 프로젝트다!) 파이썬 생활밀착형 프로젝트: 웹크롤링, 카카오톡 메시지 보내기, 업무자동화까지11가지 파이썬 프로젝트 (0) | 2021.06.03 |
| [신간안내] 개발자 취업 성공 프로젝트 #1 누가 IT시장 취업에 성공하는가: 신입 경력 지원자와 면접관을 위한 지침서 (0) | 2021.05.07 |
책에서 진행하는 예제의 소스코드는 다음 깃허브 주소에서 확인할 수 있습니다. 장별로 브랜치를 만
들어 두었으니 해당 장의 소스코드를 이용하려면 해당 브랜치로 이동한 후 참고해 주십시오. 6, 7, 8
장은 뷰를 만들기 위한 HTML 코드 내용이 길고, 지면에서 긴 코드를 확인하기에 가독성의 한계가
있습니다. 소스코드를 복사해서 인텔리제이 에디터를 통해 책의 설명을 함께 보시기를 권합니다.
'자료실' 카테고리의 다른 글
| [예제소스] 보통의 취준생을 위한 코딩 테스트 with 파이썬 : 백준 플래티넘 5 & 코드포스 파란색 랭크 달성하기 (0) | 2022.02.10 |
|---|---|
| [예제소스] 백견불여일타 Node.js로 서버 만들기 (1) | 2021.10.13 |
| [본문 예제소스] 백견불여일타 (이젠 프로젝트다!) 파이썬 생활밀착형 프로젝트: 웹크롤링, 카카오톡 메시지 보내기, 업무자동화까지11가지 파이썬 프로젝트 (0) | 2021.06.03 |
| [본문 예제소스] 백견불여일타 머신러닝 데이터 전처리 입문 (2) | 2020.09.07 |
| [파워포인트 템플릿] 사고법 도감: 문제 해결•아이디어 발상력을 높여주는 사고법 60 (0) | 2020.07.30 |
'오탈자 정보' 카테고리의 다른 글
| [오탈자 정보] 보통의 취준생을 위한 코딩 테스트 with 파이썬 : 백준 플래티넘 5 & 코드포스 파란색 랭크 달성하기 (2) | 2022.02.10 |
|---|---|
| [오탈자 정보] 백견불여일타 Node.js로 서버 만들기 (2) | 2021.10.13 |
| [오탈자 정보] 사람과 프로그래머#11 나는 주니어 개발자다 (4) | 2021.08.26 |
| [오탈자 정보] 백견불여일타 (이젠 프로젝트다!) 파이썬 생활밀착형 프로젝트: 웹크롤링, 카카오톡 메시지 보내기, 업무자동화까지11가지 파이썬 프로젝트 (0) | 2021.06.03 |
| [오탈자 정보] 개발자 취업 성공 프로젝트 #1 누가 IT시장 취업에 성공하는가: 신입 경력 지원자와 면접관을 위한 지침서 (3) | 2021.05.07 |

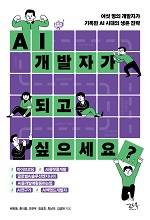
● 저자: 김설화, 문영기, 정종윤, 지찬규, 최재용
● 페이지: 460
● 판형: 신국판형(152*225)
● 도수: 2도
● 정가: 18,000원
● 발행일: 2021년 9월 10일
● ISBN: 978-89-97924-88-2 93000
[오탈자 사이트]
[강컴] [교보] [반디] [알라딘] [예스24] [인터파크]
[샘플원고]
_도서 내용
이 책은 다섯 명의 평범한 주니어 개발자들의 성장 이야기를 다룬다. 하지만 각자의 이야기는 결코 평범하지 않다. 늦깎이 취업 준비생, 사범대 졸업생, 임베디드, 산업기능요원, 비전공자 출신 개발자가 모여 글을 썼다. 각자 다양한 환경 속에서 개발자가 되기 위해 노력했고, 그 땀방울의 흔적을 고스란히 담으려 노력했다. 취준생과 주니어에게는 용기를, 시니어에겐 MZ 세대 개발자들을 이해할 수 있는 시간이 되기를 희망한다.
_대상 독자
<누가 봐야 하는가>
"이제 취업해야 할 시기는 다가오는데, 캄캄하고 막막하네"
_컴퓨터공학 전공 3학년생
"우리회사 신입 개발자 때문에 죽겠어. 도대체 무슨 생각을 하고 있는지 모르겠어. 알아서 잘하면 좀 좋아"
_10년차 시니어 개발자
"개발자들은 정말 이해가 안 될 때가 많아. 생각하는 구조가 다른가?"
_문과 출신 5년차 UX 디자이너
"나도 해외에서 개발자로 살아갈 수 있을까?"
_글로벌 개발자를 꿈꾸는 주니어 개발자
"컴퓨터 공학 전공도 아닌 나 같은 비전공자도 개발자가 될 수 있을까"
_일찍 철들어버려 벌써 취업 걱정하는 대학 2학년생
_목차
프롤로그
시니어가 먼저 읽어보았습니다
Story1_돌.돌.개(돌고 돌아 개발자가 되다)
_취업 전선에서
_개발 현장에서
_맺음말 - 빛을 만난 이곳에 서서
_이것이 알고 싶다!!
Story2_늦깎이 비전공자의 인공지능 공부 이야기
_정해둔 방향이 없었기에 가능한 나의 지금
_자기주도학습의 본원, 대학원
_시야를 넓혀, 미국으로
_딥러닝 연구자와 개발자 사이에서, TO DO LIST
_인공지능을 공부하며 읽었던 책들
_맺음말
_이것이 알고 싶다!!
Story3_잡개발자(aka.잡일꾼)에서 운동하는 개발자가 되기까지
_에피소드 1 : 1년차 개발자의 회고
_에피소드 2 : 그쪽(회사) 주니어 개발자는 안녕하신가요?
_주니어 개발자가 회사를 떠나는 이유
_마치며 : 개발자라고 개발이 인생의 전부는 아니잖아?!
_이것이 알고 싶다!!
Story4_‘한 사람의 몫’이라는 말의 무게를 버텨내는 개발자가 되기까지
_개발할 줄 모르는 개발자
_학생과 개발자 사이에서
_프론트엔드 개발자로서의 첫 커리어
_어제보다 더 프로페셔널하게
_나를 성장시킨 것들
_글을 맺으며
_이것이 알고 싶다!!
Story5_이대로 멈출 순 없다! 문과형 비전공자가 국내 SI에서 해외 개발자로 거듭나기까지
_비전공자 개발자란 무엇일까? ‒ 자바 한 명 타세요? 드럼통 개발자?
_두근두근 첫 해외 이직 시도기
해외만 넘어오면 모든 게 해결될 줄 알았다, 그러나
_두근두근 두번째 해외 이직 시도기
_그래서 어떻게 되었냐면…
_이것이 알고 싶다!!
에필로그
_주요 내용
보통의 개발자 이야기
_그들은 어떻게 개발자가 되었나?
나는 개발 경력이 많은 시니어 개발자도 아니다. 모든 임무를 척척 수행해낼 수 있는 수퍼 개발자도 아니다. 나는 캠퍼스에서 도서관에서 쉽게 볼 수 있는 평범한 보통의 취준생이었고 현재도 보통의 주니어 개발자다. 이런 내가 나의 보통의 이야기를 쓴 이유는 단 한 가지다. 취준생일 때 아팠던 여러 감정의 파편들, 주변에 누구에게 의지할 곳 없었던 고독감과 두려움을 겪은 지 얼마 되지 않았기에 현재 취준생들에게 나의 이야기가 조금이나마 보탬이 되었으면 하는 바람에서다.
_본문 중에서, 돌.돌.개(돌고 돌아 개발자가 되다)
[시니어가 먼저 읽어보았습니다]
읽기도 편하고, 지식이 잘 정리되어 있으며, 따뜻하다. 코딩에 영혼을 사로잡힌 모든 주니어에게 권하고 싶다.
_임백준(삼성전자 삼성리서치 데이타 인텔리전스랩 상무)
개발자의 길을 걷기 위한 도전 과정, 개발자의 길을 걸어가며 힘들고, 외롭고, 두려운 순간 순간의 다양한 감정들을 엿보는 것만으로도 큰 위로가 될 것이다.
_박재성(NEXTSTEP 대표, 우아한형제들에서 우아한테크코스 캡틴)
개발자가 되기를 희망하나 모호함에 어려움을 겪고 있는 분과 혹시라도 늦거나 틀렸나 하는 불안감을 느끼는 개발자들이 공감과 희망, 나아가 실전적 실천법을 찾을 수 있는 책이다.
_유석문(라이엇게임즈 기술 이사)
주니어 개발자 다섯 분의 취업과 경력에 얽힌 진솔한 경험담은 소위 말하는 네카라쿠배당토의 연예인 개발자의 성공담과는 달리 보통 사람으로서 우리가 겪는 일상이 덜 가공되고 포장되었지만 그만큼 더 가슴에 와닿는 힘이 있다.
_박재호(‘컴퓨터와 책' 블로그 운영자)
이 책은 신입 개발자가 회사에서 경험할 수 있는 내용을 현실적으로 다루고 있다. 다양한 직군, 다양한 배경의 내용이 있기 때문에 많은 분들이 읽으면 도움이 될 것이다.
_변성윤(글쓰는 개발자 모임, 글또 운영자)
-------- 이것이 알고 싶다(일부 발췌)-------------
Q. 코딩 면접에서 특히 많이 떨어진 것 같습니다. 떨어진 이유가 무엇일까요?
코딩량이 부족했던 것 같습니다. 수학문제도 많이 풀어봐야 잘 풀 수 있듯이, 코딩 테스트도 똑같습니다. 코딩을 많이 해봐야 합니다. 그래야 코딩을 한다는 행위에 익숙해지기 때문입니다.
Q. 비전공자 중에서 어떤 사람이 개발자가 되면 잘할 수 있을까요?
코딩이라고 하는 것도 결국엔 내 머릿속의 생각의 흐름들을 논리적으로 차근차근 코드로 옮겨 적는 것이어서 논리적인 사고를 할 수 있는지 여부가 중요하다고 생각합니다.
Q. 다시 학부시절로 돌아가더라도 개발자가 되고 싶나요?
네 당연하죠! 개발자만큼 즐거운 직업은 없는 것 같아요. 사실 공부하면서 돈 버는 기분이라(웃음). 물론 평생 공부해야 하는 숙명이 있지만 그걸 감안하고도 너무 매력있는 직업인 것 같아요.
Q. 백엔드 개발자로 처음 시작할 때 당황스럽고 힘든 순간이 많았던 것 같습니다. 첫 신입시절 1~2년을 잘 넘기려면 무엇이 필요할까요?
친한 회사 동료가 해준 말인데 “기분이 태도가 되지 말자!”라는 워딩이 전 크게 와닿더라고요. 지금은 이 말을 항상 머릿속에 새기고 커뮤니케이션 하려고 노력 중입니다.
Q. 4~5년 전으로 돌아간다면, 개발자가 되기 위해 준비했던 경험 중에 바꾸고 싶은 게 있나요?
그때로 되돌아간다면 분야를 가리지 않고 다양한 공부를 해보면서 내가 잘 할 수 있는 분야를 찾아보고 싶습니다.
Q. 비전공에 취성패를 거친 개발자인데요. 지금 컴퓨터만 다룰 줄 아는 인문학 전공생 3학년인데,
개발자가 되는 가장 빠른 길은 무엇일까요?
저와 같은 길을 걸어오셨는데, 우선은 당연한 말이지만 개발자 취업 공고에 지원하시는 것입니다. 지원을 하시다 보면, 각 회사별로 요구하는 공통점이 있을 것입니다. 바로 지원하셔서 합격하시지 못해도 좋습니다. 그렇다면 그 공통적으로 요구하는 사항에 대해 따로 공부하여 준비하시면 됩니다. 다른 지원자들과 차별화할 수 있는 점을 찾는다면, 다음 번엔 어느새 개발자로 일하고 있는 자신을 만날 수 있을겁니다.
_저자 소개
지은이
김설화
한국에서 근무한 지 1년 반 만에 해외로 탈출(?)해버린 개발자. 그 유명한 {비전공자+취업성공패키지} 출신이다. 무경력, 무학력, 무유학으로도 해외취업을 할 수 있다는 것을 보여주려고 노력 중이다. 현재 한국 경력보다 해외 경력이 조금 더 앞선 이제 갓 3년차를 넘은 개발자가 되었다. 현재 독일의 핀테크 은행에서 고(Go) 언어 백엔드 개발자로 근무 중이다. 좌우명은 ‘정석대로 정의롭게 살자!’이지만, 독일에서 갖은 고생을 겪다 보니 어떻게 하면 더 많은 한국인 개발자들을 더 많이 독일로 끌어 들여 나와 같은 고통을 맛보게 할지 생각 중이다.
문영기
인하대학교 사범대 수학교육과, 복수전공 통계학과 졸업 후 인하대학교 컴퓨터공학과 석사과정에 재학 중인 대학원생이다. 동시에 스타트업에서 AI 리서치 엔지니어로 반년 정도 지낸 주니어이다. 대학원생과 스타트업 주니어 개발자라는 2개의 정체성으로 살아가고 있다.
정종윤
‘재그지그’라는 필명으로 활동하고 있는 프론트엔드 개발자. 처음 이메일을 만들 때 ‘지그재그’가 이미 사용 중인 이름이라고 해서 ‘재그지그’ 로 쓰게 된 것이 작명의 계기다. 프론트엔드 개발뿐만 아니라 디자인과 UI, UX 설계에도 관심이 많다. 약 3년 간 여러 스타트업을 떠돌며 잡초같은 경력을 쌓았고, 최근에는 주니어 딱지를 떼고 더 큰 시야를 갖기 위한 고민을 하느라 시간을 보내고 있다.
지찬규
전자공학과를 졸업하고 임베디드 개발을 하고 싶어 제조업 개발자로 취업을 하게 되었지만, 현실은…(왜 개발자로 뽑고 볼트 쪼이는 일을 시키는 건가요?!) 첫 직장에서 2년 동안 잡일꾼(CS, 시험, 출장)으로 우여곡절을 거쳤다. 현재는 판교에 있는 IT 회사에 백엔드 개발자로 커리어 패스를 한 2년차 주니어 개발자이며, ‘운동하는 개발자'로 거듭났다. 가장 좋아하는 개발과 취미인 운동을 열심히 하면서 ‘피트웨어 제이 [운동하는 개발자]' 라는 유튜브 채널을 운영하며 재밌게 지내고 있다.
#헬스는고립 #인생도고립 뽀시래기 개발자 화이팅!
최재용
개발자가 되고 싶다는 마음의 확신을 갖기까지 다소 시간이 걸렸지만 결국 개발자로서 첫 발을 떼는 데 성공했다. 좋은 개발자, 좋은 사람이 되고 싶다 라는 막연한 목표를 가지고 살고 있지만 아직 이 단어의 정의를 스스로 내리지 못하고 있다. 하지만 언젠가 이러한 단어가 어울리는 개발자, 사람이 되기 위해 계속해서 고민하고 행동으로 실천하기 위해 노력 중인 주니어 개발자다.
_상세 이미지

_끝
'신간소개' 카테고리의 다른 글
| [신간소개] 백견불여일타 Node.js로 서버 만들기 (2) | 2021.10.13 |
|---|---|
| [신간안내] 백견불여일타(이젠 프로젝트다!) 스프링 부트 쇼핑몰 프로젝트 with JPA (6) | 2021.08.26 |
| [신간안내] 백견불여일타 (이젠 프로젝트다!) 파이썬 생활밀착형 프로젝트: 웹크롤링, 카카오톡 메시지 보내기, 업무자동화까지11가지 파이썬 프로젝트 (0) | 2021.06.03 |
| [신간안내] 개발자 취업 성공 프로젝트 #1 누가 IT시장 취업에 성공하는가: 신입 경력 지원자와 면접관을 위한 지침서 (0) | 2021.05.07 |
| [신간안내] 사람과 프로그래머 #10 죽을 때까지 코딩하며 사는 법 (0) | 2021.04.05 |